Following on from part one of my conference review, here are my favourite talks from the middle part of the conference.
Social media and spatial modelling – Tweets and museums
Robin Lovelace (Newcastle) won best paper at the end of the conference, for this talk on examining tweets “geofenced” around many local museums, to see from where these people travelled and what they had to say about the museum.
Agent Based Models and GIS for disaster zones
Sarah Wise (George Mason University & UCL) presented a chapter from her Ph.D on the use of GIS in immediate post-disaster zones, focusing on the Haiti earthquake. OpenStreetMappers quickly mapped Port-au-Prince and other badly damaged areas, using satellite and aerial imagery made available, and Sarah studied the resulting crowdsourced GI information. An agent-based model was then used, with the fractured road network, to model how survivors would move to locations where food and other aid was made available, the visualisation of the model output showing how well different areas, some with considerable damage to the road network, were served in the days after the disaster. Sarah won Best Paper on Spatial Analysis which is awarded by CASA based on submitted abstracts for the conference.

Visualising activity spaces of urban utility cyclists
This talk by Seraphim Alvanides (Northumbria) showed that utility cyclists – those aiming to get from A to B as efficiently as possible – are often poorly served by dedicated cycling infrastructure. Where a road route is shorter than a cycleway, more people than you might expect will take the former, and the talk showed some graphics of flows along roads and paths to demonstrate this.
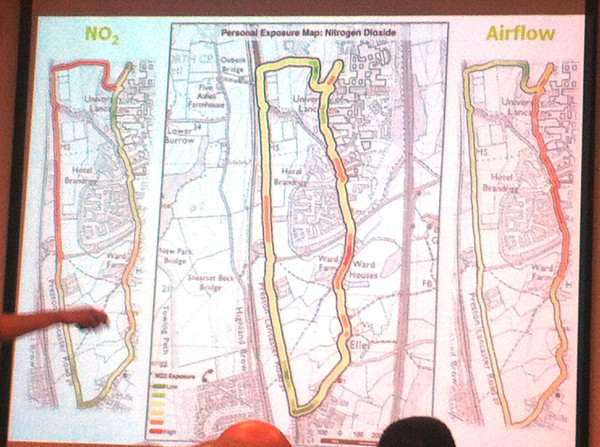
Exposure to air pollution: the quantified self
Jonny Huck (Lancaster) gave one of my favourite presentations of the conference, and certainly one of the most visually impressive. It first explored personal sensors (for heart rate, breathing etc) and the internet of things (with small internet-connected devices), then combining the two to detail a device, based on Arduino, e-Health, Waspmote and Android, for monitoring exposure to pollution – combining breathing rate and air pollution levels – for a walk around the campus at Lancaster University, where climbing up steep hills in the campus had as much impact as walking alongside major roads. It’s early stage research and I’m not sure the very intrusive breathing monitor is going to catch on, but certainly points to a quantified future. At CASA, we have started to acquire and evaluate personal and environmental sensors, with FitBits and pollution sensors in the office, so a CASA-centric approach to this kind of research might not be too far off.
The final session of the day took the form of a series of plenaries about interdisciplinary research. While some of these were interesting in their own right (particularly, an unexpected one on cellular biology!) I didn’t get as much out of them as I did from the paper sessions.
At the end of the second day of the conference most people went to the dinner – I didn’t have a ticket for this though, so headed back to central Glasgow with Addy, who’s written up his thoughts on the conference here on the EDINA Go-Geo blog. My comments on the final day will appear in the final part, tomorrow.










 My visualisation attempts be the best of both worlds, by retaining the familiar geographic shape of the UK and its towns and cities, but not swamping the map with colours in all areas, and indeed ensuring that unpopulated areas have no colour. This is possible because
My visualisation attempts be the best of both worlds, by retaining the familiar geographic shape of the UK and its towns and cities, but not swamping the map with colours in all areas, and indeed ensuring that unpopulated areas have no colour. This is possible because 



