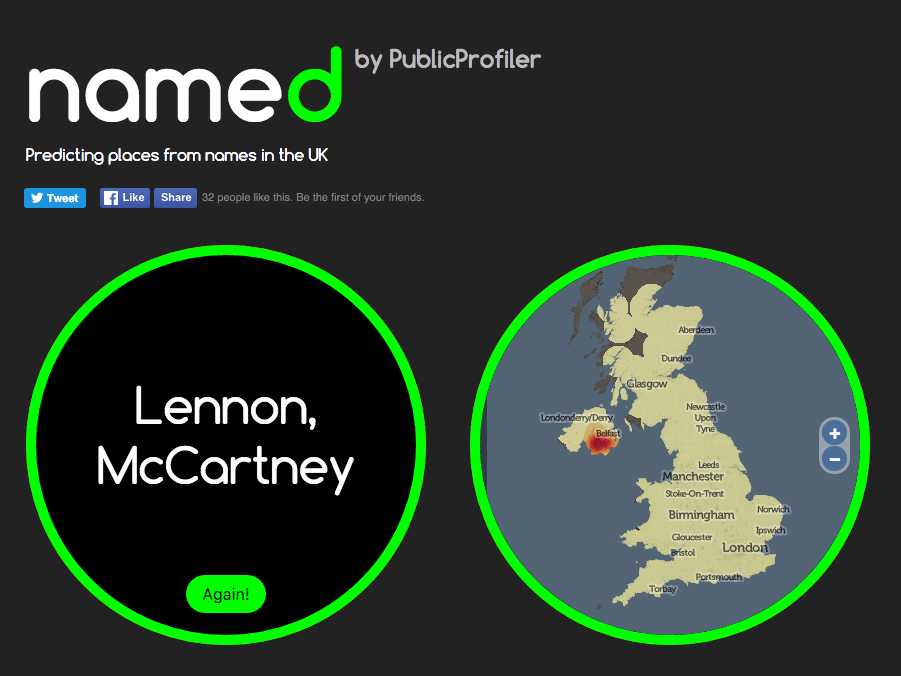
named is a little website that I have recently co-written as part of an ongoing ESRC-funded project on UK surnames that we are conducting here at UCL Department of Geography. I put together the website and adapted for the UK some code on generating heatmaps showing regions of unusual popularity of a surname, that was created by researchers in the School of Computing, Informatics & Decision Systems Engineering at ASU (Arizona State University) in the USA.
The website is deliberately designed to be simple to use and “stripped down” – all you do is enter your surname and the website maps where in the UK there is an unusually high number of people with that surname living. There is also an option to enter an additional surname (for example, a maiden name for yourself or your partner, or the name of a friend) – and, by combining heatmaps of both names, we try and draw out where we think you might have met each other, or grown up together.
The Research
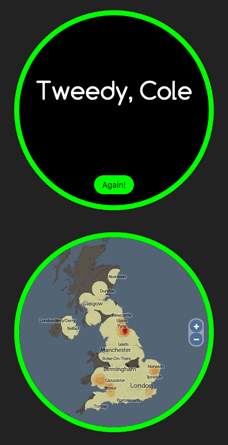 Of most interest to us is the quality of the technique with pairs of surnames. It is well known already (for example, J A Cheshire, P A Longley (2012) Identifying Spatial Concentrations of Surnames, International Journal of GIS 26(2) pp309-325) that most traditional UK surname distributions remain surprisingly unchanged over many years – internal migration in the UK is a lot less than might be traditionally perceived. One of the research questions in the underlying project is to see whether this extends to marriages and other pairings too. So we encourage you to use this mode and help us understand and evaluate pairing surname distributions and patterns.
Of most interest to us is the quality of the technique with pairs of surnames. It is well known already (for example, J A Cheshire, P A Longley (2012) Identifying Spatial Concentrations of Surnames, International Journal of GIS 26(2) pp309-325) that most traditional UK surname distributions remain surprisingly unchanged over many years – internal migration in the UK is a lot less than might be traditionally perceived. One of the research questions in the underlying project is to see whether this extends to marriages and other pairings too. So we encourage you to use this mode and help us understand and evaluate pairing surname distributions and patterns.
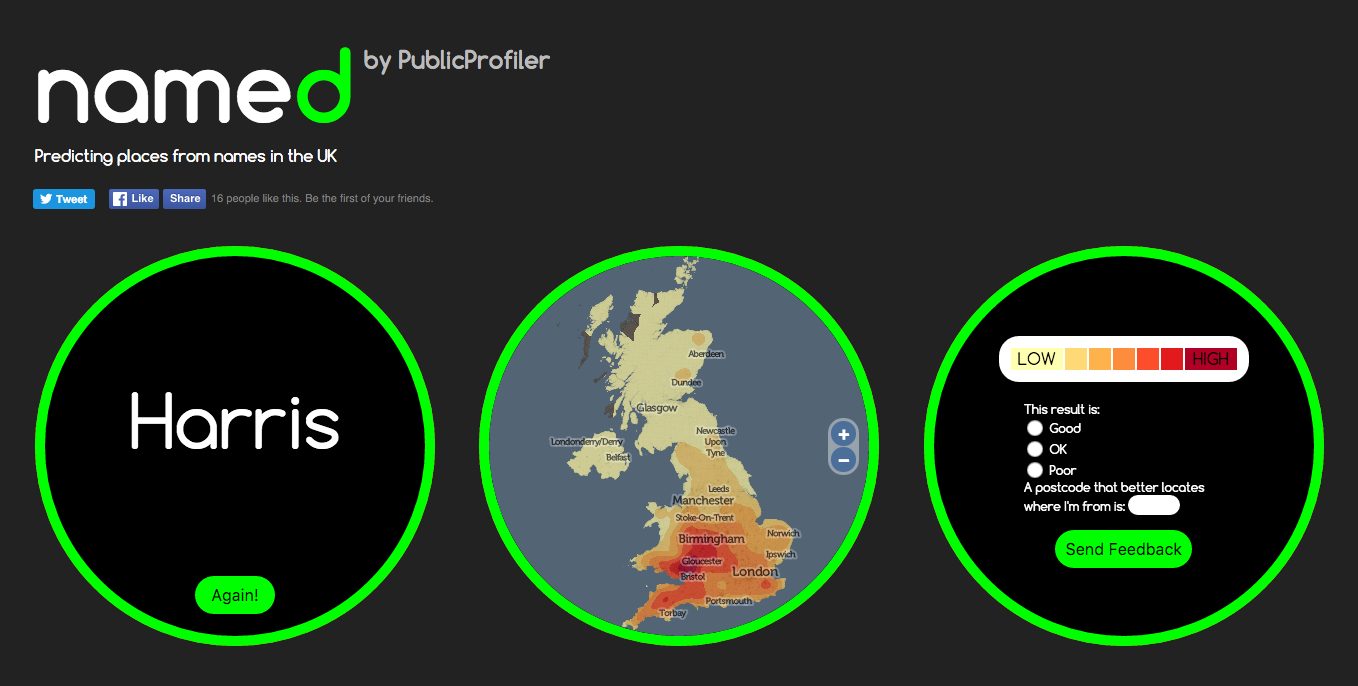
The site is also a useful information gathering tool – we are only in the early stages of evaluating the validity or accuracy of this method – we know it works well for certain regional UK names which are not too popular or too rare, at least. We ask for optional quick feedback following a search, so we can evaluate if the result feels right for you. So far, with the website been operational for around a week, nearly 10% of people are giving feedback, and around half of those suggest that it is good result for them. If it doesn’t highlight where you live now, it might be showing your ancestral home or other region that you have a historical link to. Or it may be showing complete rubbish – but let us know either way!
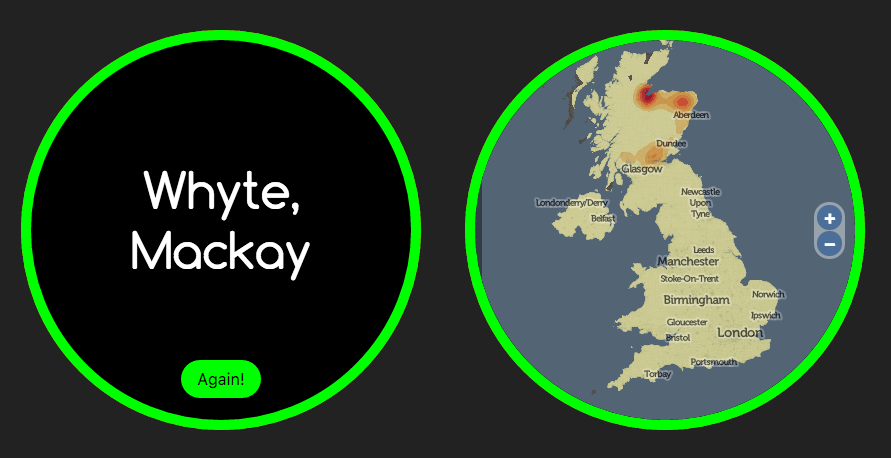
Try it out for yourself – visit here and see what it says for your surname. The site should be quite quick – it will take up to 10 seconds for names which have not already been searched, but is much faster if getting information that’s previously been searched for.
How it Works
The system is creating a probabilistic kernel density estimate (KDE), based on surname distributions (in a postcode) for an old electoral roll. It finds the relatively frequency/density of the surname compared with the general population in the area. So, in most cases, it will often highlight an area in the countryside – a sparse population, but maybe with a cluster of people with that surname. As such, it will only rarely highlight London and the other major cities of the UK, except for exceptionally urban-centric surnames, typically of foreign-origin. The method is not perfect – the “bandwidth” is fixed which means that neighbouring cities and other population fluctuations can cause false-positive results. However, we have seen enough “good” results that we think the simple has some validity, with the structure of the UK’s names.
Design
On a design perspective, I wanted to build a website that looks different from the normal “full screen slippy maps” that I have designed for a lot of my research projects. Maps are normally rectangular, so I played with some CSS and a nice JQuery visual effects library, to create a circular map instead which appears to be on the back of an information disc.
Data Quality and Privacy
The map is deliberately small and low on detail because having a more detailed map would imply a higher level of precision for the underlying names data than can actually be justified. The underlying dataset has issues but is considered to be sufficient for this purpose, as long as the spatial resolution is low. Additionally, for rare names where a result may appear for only a small number of people with that name (when in rural places) we don’t want to be flagging individual villages or houses. The data’s just not good enough for that, for many names (it may well be good for some) and it may imply we are mapping exact data over someone’s house, possibly raising privacy issues – we are not, the data is not good enough for that but by coincidence it may still happen to line up with a very local feature if it was high res.
It should give an indication into the general area where your name is unusually popular relative to the local population there (N.B. not quite the same as where your name is popular in absolute terms) but I would be wary of the quality of the result if you were identifying a particular small town or exact location.
[A little update as one user worried that it was just showing a population heatmap. This would only happen for names which have a higher relative population in more dense area of the UK. Typically, older common foreign origin names will most likely show this, as foreigners traditionally migrate to cities in the UK first. The only name so far that I’ve seen it for (I haven’t tested it for many) is Zhang which is a very common surname. Compare Zhang (left) with an overall population heatmap (using the same buffer and KDE generation as the rest of the maps):
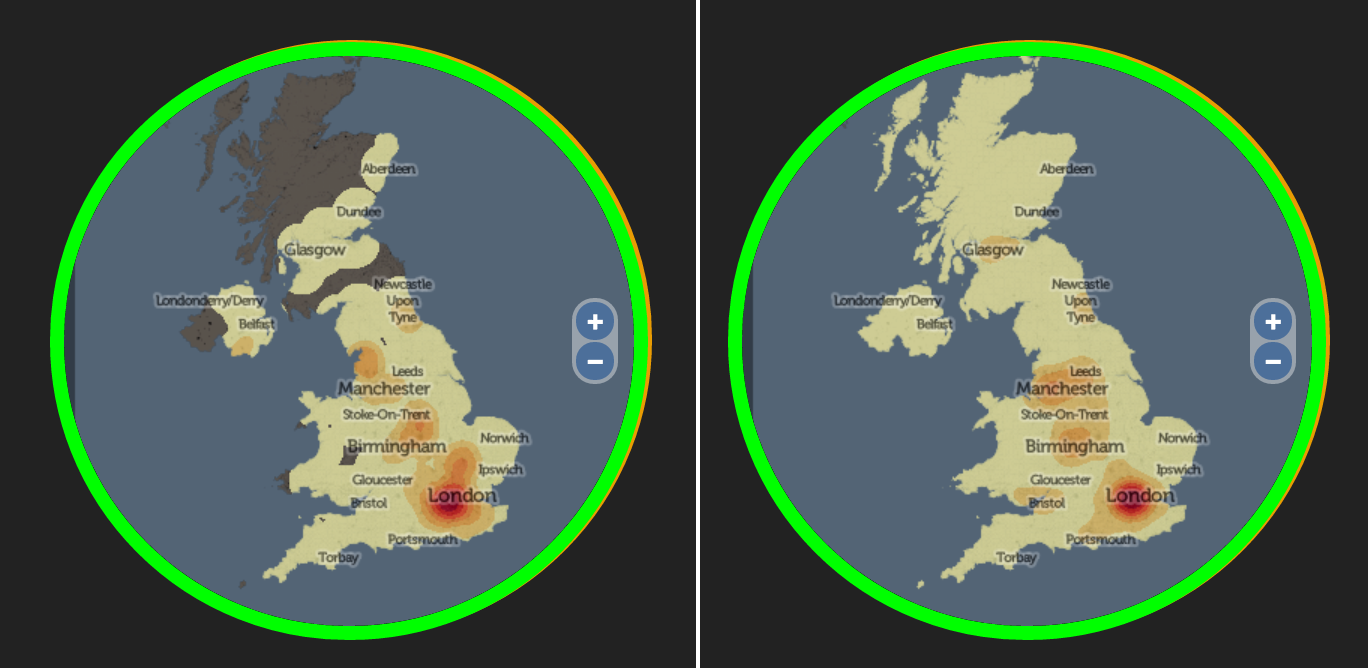
Some newer foreign origin names show an even more pronounced urban tendency, such as Begum and Mohammed.]
More…
Try named now, or if you are interested in surnames across the world, see the older WorldNames website, and for comparisons between 1881 and 1998 distributions in the UK, see GB Names.
If named shows “No Data” and you have entered a real surname, this may be because there are only very few of you on the UK – and in this case, I show the “No Data” graphic to protect your privacy. Otherwise I’d be mapping your house – or at least, your local neighbourhood.
38 replies on “named”
Okay, using the circle-for-two-names at the right also did not work. Clarke (then) Berry did work. So perhaps the server is retaining data it doesn’t need to.
I just put a long post at the other place. I’ve just tried the two names facility for the first time. So Berry, Clarke or Berry,Clarke (no space). They both think I’m asking for Berry-Clarke and return “No Data”.
Your genetic make-up completely concurs with the nature of the British Isles. Rather than travelling abroad, we have absorbed a little of all those successive waves of immigration; Iberian, Saxon, Scandinavian, Norman. Welcome to Europe.
Suddenly NAMED no longer works for me. Circles come up, with a box for Again, but no place to enter surname, and no response to clicking on circles
Hi Jim, should be working now!
Can you tell us what date(s) the data are from?
If you want to check your Irish results, you could compare with John Grenham’s surname site. Also, I have the full Irish census data for 1901 and 1911 if you want to play with it.
Hi Dermot, the data is “most recent available at the time of publication” – unfortunately we don’t have more detail than that, but it should be no more than a few years out of date. We certainly would be interested in historic census data for Ireland – please drop me an email at o.obrien (*at*) ucl.ac.uk
This is fascinating. I just wish the map displayed full screen rather than in a tiny window.
A larger map would imply a higher level of precision with the data than is the case. The very nature of creating a fixed-bandwidth window blurs the underlying data by many kilometres. This is why the map is deliberately chosen to be small.
My maiden name is Gossage. The highest concentrations are to be found in Warwickshire and Worcestershire (because places like Kings Norton and Kings Heath in Birmingham were once in Worcestershire). I am a member of the Guild of One-Name Studies and have been conducting both surname and DNA studies on the name Gossage. Before my father died two years ago, I took his DNA which was predicted to be of the E-M35 haplogroup. I am currently awaiting the results of a BigY test at FTDNA. It is believed, that the Birmingham Gossages are not related to the Gossages in Lancashire.
[…] There had always been a Baggins at Bag End. Computed by Oliver O’Brien. […]
Hi Oliver, I checked out my Mother’s maiden name Attle, and was fascinated to see the main location in the North East. I actually researched that anomaly a few years ago, as the name was East Anglian until, as it turned out, a couple of enterprising brothers left their family smallholding near Holt in Norfolk to join the industrial revolution sometime in the 1860s. One went into steel, and the other; William, went down the mines. He married Barbara, they had 10 kids, and now there are many more Attles up there than anywhere else in the UK.
I kept seeing Ernest from Crook and Billy Row, which piqued my original interest, as that’s my husband’s Father’s birth area. And in the 1891 Census Ernest appears with Dad William, Mum Barbara and siblings next door to my husband’s great-great uncle! It was a small world in them days. Btw William always put his birthplace as Durham, but I wonder how long it took him to lose his Norfolk accent?
[…] data visualization blog post got this project started. The public-access web portal provided the qualitative data for […]
Hi,
Really like this – very simple & clean design, but lots of info. Question: do you want my current postcode, where I was born, or where my father and a couple of generations back came from? (all different).
Hi Carole, it’s a good question, the postcode for us is most useful for “couples” as we are trying to see how good the system is at matching where people met.
For individual names, it is less useful as we already “know” the locations – after all, that is what is being mapped. The location where you’ve spent the most amount of time in the last few years is probably going to be a closest match to what we are mapping.
Hi Oliver,
Wonderful work! Is there anyway to run a series of intersecting surnames? I am trying to work out a rational way to relate genetic genealogical data with your data tool.
Currently we can convincingly trace our family by paper and/or DNA to County Antrim, Northern Ireland, but only as early as the 1730s.
I have tested for a Y-DNA haplogroup SNP (single nucleotide polymorphism, useful for family and deeper, clan-level kinship, as well as ethnicity and prehistoric migration information) called ZP148. It is Insular Celtic, but more likely deriving from the Britons of The Old North https://en.wikipedia.org/wiki/Hen_Ogledd, rather than from the Gaels of Ireland or Scotland. This SNP is associated with a mixture of Anglo-Saxon and anglicized Gaelic surnames: McMichael, Reynolds, Johnson/Johnston, Clark, Caldwell and Carll/Carle https://www.familytreedna.com/public/R-DF49/default.aspx?section=yresults. Based on predicted ZP148 SNP from STR (short tandem repeats aka genetic fingerprinting) haplotypes, there is an even larger set of DNA kits, with the same mix of Anglo-Saxon and anglicized Gaelic surnames: Caldwell, Carll/Carle, Clark, Connors, Henderson, Johnson/Johnston, Kelly, Kennedy, Loafman, Lockhart, Loughman, Mackenzie, MacWhirter, McCune, McKenzie, McMichael, Merrill, Milling, Pollock, Reynolds, Richardson, Taylor and Wilson.
There are only a few places where the right sorts of political-cultural-linguistic forces of mediaeval times that would have brought these groups together in such a way that would work out like this – mixed Anglo-Saxon and Gaelic culture superimposed on British genes. I think a reasonable hypothesis is a geographical locus in western Britain, in what is now southwest Scotland and northwest England, in particular the lands around the Solway Firth.
Using the Couple function of Named, if one serially pairs my surname, McMichael, with the other surnames from the R-DF49 and Subclades Project database sharing the SNP as well as predicted, those pairs tend to most strongly localize to Kirkcudbrightshire/Dumfriesshire, Northern Ireland or both.
I have a very strong STR match to a Richardson. The same thing happens with McMichael & Richardson. Interestingly, the 2nd most intense hotspot for Richardson alone is on the Cumbrian side of the Solway Firth. Also, serially pairing Richardson with the other surnames from the R-DF49 and Subclades Project database that share the SNP as well as predicted, those pairs tend to most strongly, and recurrently localize to Cumbria.
I think it would be interesting to run all these names together in a string. I am thinking a lot of noise and extraneous info would drop out and produce a very hot spot in Cumbria and a secondary hotspot in Galloway and Dumfries with perhaps contiguous Ayrshire, as well as a third locus in Northern Ireland.
Sláinte
Why is the Isle of Man missing?
Please will you explain the darkened areas. For some of the names I am looking at it seems very odd that they are not appearing in some of the areas shaded in grey.
I think this is potentially a very useful aid in researching Family History. I have used it on a few names and have found it supports information I have already discovered.
Thank you for making this available.
Hi Linda, the Isle of Man is not part of the UK. Grey indicates no results at all in the area. Just one result is enough to turn other parts of the map yellow (indicating the lowest amount). This is a quirk of the map and actually we should really be colouring all such areas with the yellow colour, because the difference between 1 person and no people is not significant.
Do note that, while for many names there is a correlation with name history, it is a map of the present not the past – i.e. it is showing current distributions of the name, not historic ones.
I tried the surname Gallop. The result was fairly low over most of the country, but the one exception was a hot spot in Scotland on the mainland near the Isle of Skye. This is a complete surprise. I come from the opposite end of the country, on the south coast, in Hastings. As far as I can tell our surname goes back several generations there and in local books the surname appears unexpectedly often. It would be intriguing if the Scottish connection was borne out in practice.
The map doesn’t show origins or history, but rather places where you are unusually likely to bump into somebody with that name. In very rural areas (such as parts of the Highlands, you don’t need to have very many people with a name, for it to show up as a hotspot, because there aren’t very many people with any other names either. Whereas, in more populated parts of the country, you need a large number of people. Bear this in mind. It may well be that there are many more Gallops in Hastings than in the whole of the Scottish Highlands, but you are less likely to come across one, if you pick a random set of 100 people in both places.
Hello,
Thank you for the website, most valuable.
I can from my family research comment as follows. Source information from 1700 onwards for Hampshire, Dorset and Wiltshire.
Guy – you show a density at Marnhull , Dorset. My records show Guy at Ringwood
Hampshire from late 1600 onwards and residence until now.
Clifford – you show a density centered left of Swindon, Wiltshire. My records show
Clifford at Highway to the south of Swindon from the first census.
Price – you show a density at Brecon. My records show a possible connection to the
area prior to 1800
Gue – you show a density at Oban. Not previously known to me. The name is
recorded for several families at Ringwood c .1700
Hope the above is interesting.
Yours faithfully
Eric Guy
[…] Creator Oliver O’Brien explained the functioning : […]
I have been typing in names of hobbits. Most of them show hotspots where JRR Tolkien grew up. Fortunately there were a few dramatic exceptions, or I’d have suspected that you put Baggins and Bolger into your database by hand as an Easter egg.
There are a few special codes, but not those!
I presented a paper about hobbits based on results of your tool at the New York Tolkien Conference. Looks like J.R.R. Tolkien did it on purpose.
http://www.idiosophy.com/2016/07/ardagraphic-information-systems-the-paper/
Hi Oliver, I was wondering if you could point me towards this code on generating heatmaps, if possible. It looks like a useful starting point for a project of mine.
Thanks!
Hi Douglas, this particular code is not released, however try searching for KDE map code.
Yes. Right on. With nearly 40 years of research in North Yorkshire on the Kettlewell line, starting in the early 1500’s in Howden (not N Yorks I know) and thence to the areas in and around Brompton, Burneston, Bedale, Exelby and Carthorpe.
I Love GIS and consider maps as artwork. This is a merging of two of my favourite interests
Thanks for the great work!
Larry Kettlewell
Calgary, AB Canada
It would be a lot easier to use if you had not disabled zoom on mobile devices. I literally can’t read half the text on that page.
Great stuff. Results on my Denison, McKibben and Casey seem to gel with my Ulster research. Husband’s Bells and Keith’s also.
Yes completely accurate. I’ve spent years putting together my BEACH family tree and we never strayed far from a 25 mile radius of Monmouth where three shires meet. Got back to about 1724 with confirmed family, but found records for Newent that might confirm the origin of the surname as there it shows the name between the late 1500’s and mid 1600’s goes from Beche to Beache, to Beach. Which I like to think confirms the Norman (Conquest) belief that the name comes from the “de la Beche” family. They were from Flanders but were awarded land for support / loyalty to the crown. I found one Guilliam de la Beche was a Marcher Lord which would place him in right at the centre of the Beach family hot spot.
One thing you might be interested in is that as I’ve researched my family tree lines back on average 300 years, nobody born outside the UK. I recently had a DNA test expecting to see my lot well and truly home grown as it were, but as you’ll see I’m not as British I should be. The % in brackets is what they would expect my family profile to show (I think?)
GREAT BRITAIN 44% (60%)
WESTERN EUROPE 33% (63%)
IRELAND 14% (95%)
SCANDINAVIA 5% (85%)
TRACE ELEMENTS ALSO FOUND FOR
IBERIAN PENINSULAR 3%
FINLAND / NORTH of RUSSIA 1%
cheers Fred Beach
My family surname ‘Squire’ is usually connected to a small village near York, where there is a graveyard full of us! Not a common name, and so I am very surprised to see the only hot spot is in North Devon where I had no idea there were any of us at all.
Just a suggestion as low frequency names can be just as frustrating as high frequency ones, but rather than show “no data” would it not be appropriate to have the search simply state the county it is present in. It would seem to me that it would be enough to protect whoever is living there but still give accurate information that could be followed up on.
Many thanks for an interesting website. The result for my surname ties in closely with what I’ve seen in my family history research and it’s confirmed where I think I need to focus in future.
Thank you for the Morris surname review. I have been told there was a connection to the Stafford area. My Gt. Gt. Grandfather was born in Bolton , and I think the generation before him was living there to not got to his birthplace yet.
I’m a Whitehouse. We’re all from Birmingham. People here in New York get my name wrong, because nobody’s called Whitehouse.
Great site. For the Churchill name your data concurs very closely with the genealogical research that I’ve been doing for over 30 years. It’s good to get further corroberation of from where my ancestor migrated to Plymouth Colony in America 370 years ago.
My two (grandparent) names (Leggett and Noble) about whom I have researched back to the 18thC, concur with your visualisation.
Congratulations!
The only problem is that the outlier returns will tempt me into more hours of scratching the archives!!