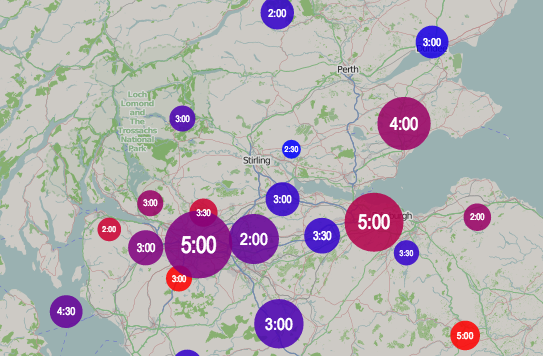
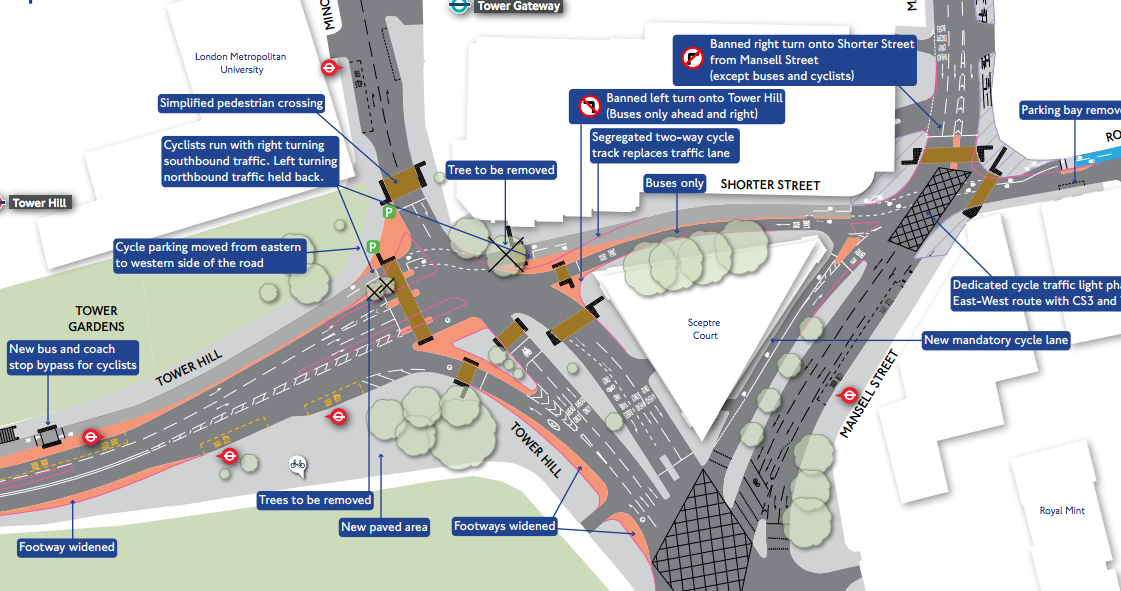
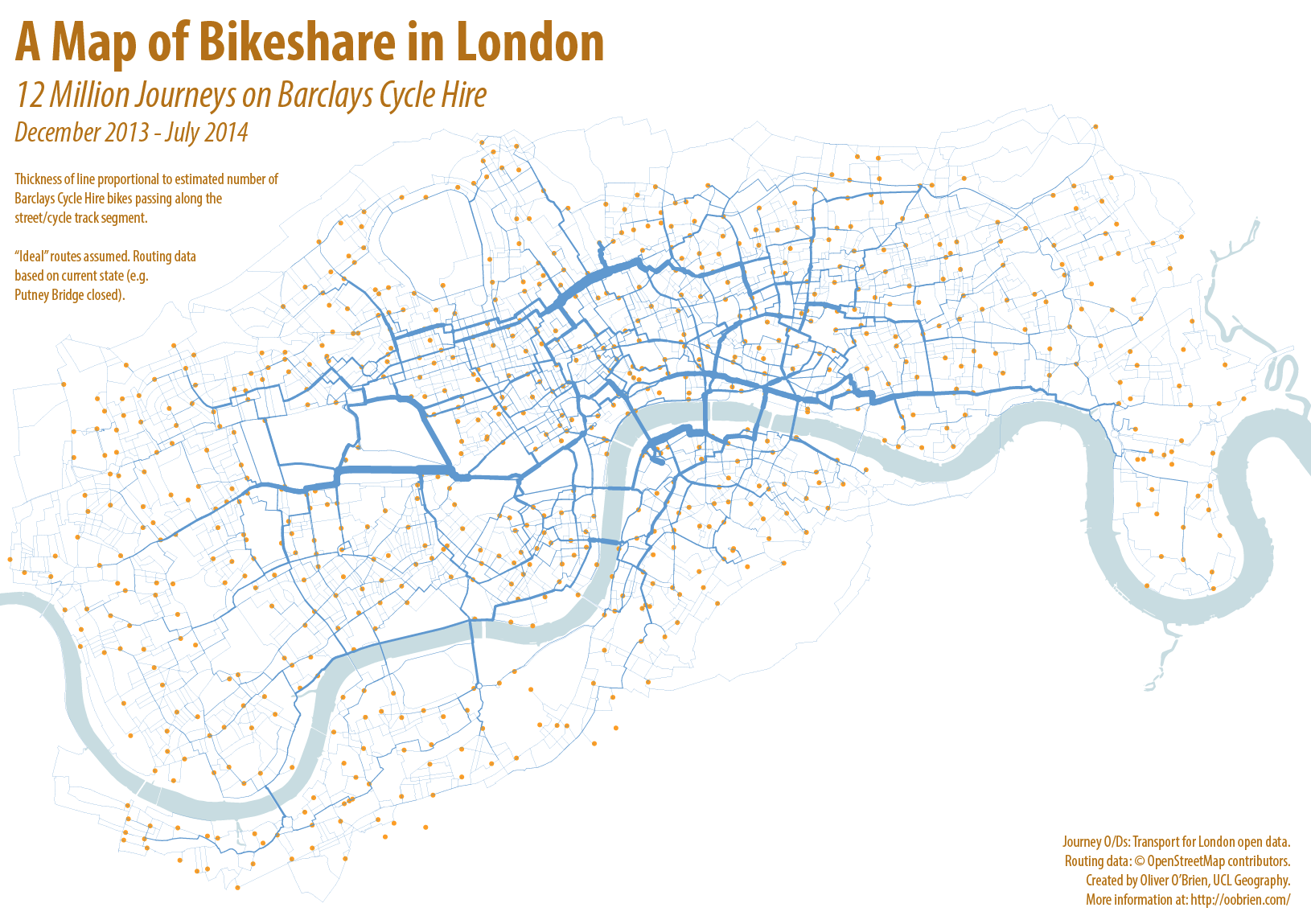
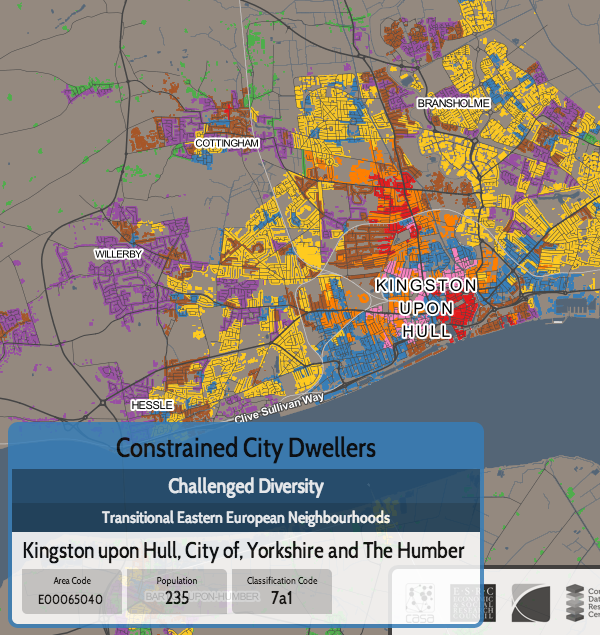
I was in Vienna for most of last week, presenting at a satellite workshop of the GIScience conference, before joining the main event for the latter part of the week.
GIScience is a biennial international academic conference, alternating between America and Europe. At the intersection between geography, GIS and information visualisation. It is very much academically focused, which contrasts strongly with FOSS4G (GIS technology), WhereCamp (GIS community) and the AGI (GIS business).
My highlights for this year’s conference:
- Jason Dykes (City) gave a keynote on balancing geovisualisation and information visualisation. As ever with presentations from City’s GICentre unit, the graphics were presented by way of various live demos and compellingly explained.
- UCL Geography/CEGE had a strong presence of the conference and various of my colleagues gave presentations, a number focusing on using geolocated social media, both as a tool for research (e.g. population synthesis) and for research itself. There was also an unveiling of LOAC (UCL/Liverpool), a classification specially built for London, further details on this to follow soon as LOAC is signed off and rolled out.
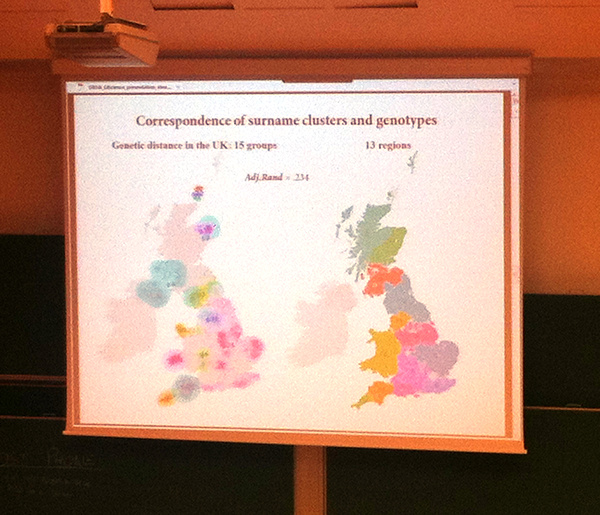
- Another UCL Geography presentation on comparing surname clustering and genotype clustering in the UK
- A interesting presentation from TU Eindhoven on automatically creating and simplifying network diagrams using circular arcs.
- Automatic Itinerary Reconstruction from Texts (LIUPPA/Pau) – showed how a fairly accurate map can be made simply by scanning prose, and otherwise unknown locations of places can be roughly determined by their textual relations to other, known places.
Many of the talks appear in an LNCS proceedings book.
Outside of the conference, much Wiener Schnitzel and Gelato was consumed, and historic old Vienna was explored. A highlight was conference drinks in the huge barrelled halls underneath the very grand city hall.